




In the early days of Deep Learning, the industry was obsessed with “Bigger is Better.” We saw the rise of models with trillions of parameters that required the energy of a small city to train. However, in 2026, the paradigm has shifted. As we deploy AI to Edge Computing devices and mobile smartphones, the new gold standard is efficiency. This shift is powered by Neural Network Optimization.
Optimization is the process of fine-tuning a model’s architecture and weight parameters to achieve the highest possible accuracy with the lowest possible computational cost. Whether it is reducing latency for autonomous vehicles or lowering the carbon footprint of data centers, Neural Network Optimization is the bridge between a laboratory prototype and a real-world product.
1. What is Neural Network Optimization?
At its core, Neural Network Optimization refers to the mathematical and structural techniques used to minimize the “Loss Function”—the difference between the model’s prediction and the actual truth.
The Two Pillars of Optimization
-
Training-Time Optimization: Improving the speed and stability of the learning process (e.g., better optimizers like AdamW or Lion).
-
Inference-Time Optimization: Reducing the size and complexity of a pre-trained model so it runs faster on local Hardware Performance (e.g., Pruning and Quantization).
2. Advanced Training Optimizers: Moving Beyond SGD
The choice of optimizer determines how a model “walks” through the high-dimensional landscape of data to find the lowest point of error.
The Evolution of Adam and RMSProp
While Stochastic Gradient Descent (SGD) was the foundation, modern Neural Network Optimization relies on adaptive learning rates. In 2026, the Lion (Evolutive Sign Momentum) optimizer has gained popularity for its memory efficiency, often outperforming Adam in large-scale transformer training by using only the “sign” of the gradient.
Weight Decay and Regularization
To prevent “Overfitting”—where a model memorizes the training data but fails in the real world—optimizers now integrate advanced weight decay. This ensures the model stays “lean” and generalizes well to new, unseen information.
-
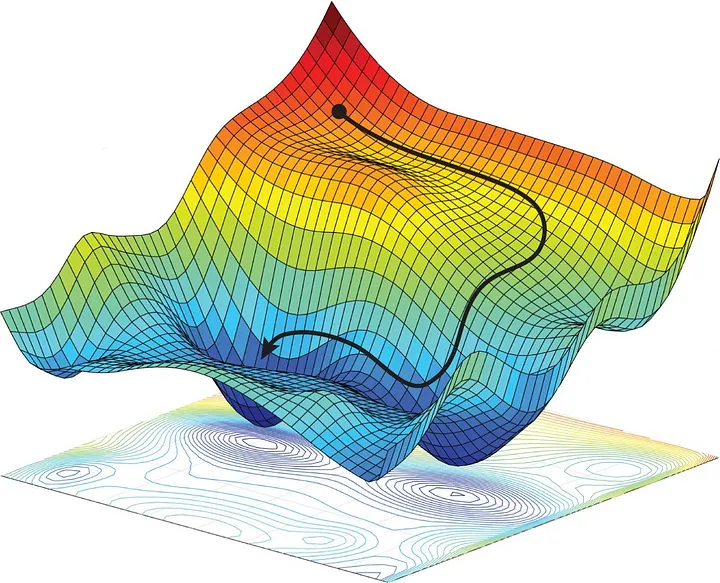
ALT Text: Visualization of loss landscape optimization in deep learning.
-
Description: A 3D topographical map illustrating how neural network optimization algorithms navigate complex mathematical gradients to reach the most accurate state.
3. Structural Optimization: Pruning and Sparsity
One of the most effective Neural Network Optimization trends in 2026 is “Pruning”—the digital equivalent of gardening.
What is Weight Pruning?
Studies show that in many Large Language Models, up to 50% of the neurons are redundant; they contribute almost nothing to the final output. Pruning involves identifying these “dead” connections and removing them.
-
Unstructured Pruning: Removing individual weights, creating a “sparse” matrix.
-
Structured Pruning: Removing entire layers or channels, which is much easier for standard GPU Hardware to accelerate.
The Rise of Sparse GPT
In 2026, we are seeing the rise of “Sparse Transformers.” These models use Neural Network Optimization to only activate a small fraction of their parameters for any given query, reducing power consumption by up to 80% without losing intelligence.
4. Quantization: Shrinking the Brain
If Pruning is about removing neurons, Quantization is about reducing the precision of the remaining ones.
From FP32 to INT8 and Beyond
Traditionally, AI models used 32-bit floating-point numbers (FP32) to represent weights. Through Neural Network Optimization, we can compress these to 8-bit integers (INT8) or even 4-bit (INT4).
-
Benefit: A 4-bit model takes up 8x less memory than an FP32 model.
-
Efficiency: This allows a massive model that previously required a server rack to run locally on a Copilot+ PC with an NPU.
-
ALT Text: Neural Network Quantization process from FP32 to INT8.
-
Description: A technical diagram showing how high-precision mathematical values are mapped to a smaller discrete range to save memory during inference.
See also
5. Knowledge Distillation: The Teacher-Student Model
Neural Network Optimization doesn’t always happen within a single model; sometimes, it involves a transfer of power.
How Distillation Works
A large, highly accurate “Teacher” model (like GPT-4) is used to train a smaller “Student” model (like a mobile-optimized SLM). The student doesn’t just learn the right answers; it learns how the teacher thinks by mimicking its probability distributions.
-
The Result: A student model that is 1/10th the size but retains 90% of the teacher’s capability.
6. Real-world Applications of Optimized Networks
Why does Neural Network Optimization matter for the end-user?
Autonomous Vehicles and Drones
For a self-driving car, a 100ms delay in processing a “Stop” sign is unacceptable. Optimized networks allow for “Real-time Inference” at the edge, ensuring safety-critical decisions happen in microseconds.
AI on Smartphones (On-Device AI)
In 2026, your phone’s camera uses optimized neural networks to perform “Live Bokeh” and low-light enhancement. Because the model is optimized, it doesn’t overheat your phone or drain your battery in minutes.
Healthcare: Wearable Diagnostics
Medical wearables use Step-by-Step AI Implementation to monitor heart rhythms. Neural Network Optimization ensures these devices can run for months on a tiny battery while maintaining the accuracy of a hospital-grade EKG.
7. The Hardware Synergy: NPUs and Optimization
Optimization is a two-way street between software and silicon.
-
NPU Acceleration: Modern Neural Processing Units (NPUs) are specifically designed to handle the “Sparse Matrix Multiplication” that comes from pruned models.
-
Memory Bandwidth: Optimization reduces the amount of data that needs to be moved from RAM to the processor, which is the primary cause of heat and battery drain in 2026 devices.
-
ALT Text: Modern NPU architecture designed for optimized neural networks.
-
Description: A schematic of a silicon chip highlighting the specialized cores meant for accelerated AI math and low-power inference.
8. Hyperparameter Tuning: The Art of Fine-Tuning
A core part of Neural Network Optimization is finding the right “Hyperparameters”—the settings used to control the learning process.
-
Learning Rate Schedulers: Starting with a high learning rate to learn quickly and “cooling down” to a low rate to settle into a precise solution.
-
Batch Size Optimization: Balancing the speed of large batches with the “noise” of small batches that often helps models escape local minima.
-
Automated Tuning: Using Automated ML (AutoML) to run thousands of simulations to find the “Perfect Recipe” for a specific neural architecture.
9. Ethics and Sustainability: Green AI
In 2026, Neural Network Optimization is a key pillar of Sustainable Tech Innovation.
Training a single large model can emit as much carbon as five cars over their lifetimes. Optimization reduces the “FLOPs” (Floating Point Operations) required, directly correlating to a reduction in CO2 emissions. Many cloud providers now offer “Carbon-Aware Optimization” tools that schedule training when renewable energy is most abundant on the grid.

10. Conclusion: The Lean Future of AI
The era of “Brute Force AI” is coming to a close. As we look toward 2027, the focus of the global tech community is on “Lean Intelligence.” Neural Network Optimization is the discipline that makes this possible.
By shrinking models, reducing precision, and pruning redundancy, we are moving toward a future where powerful AI isn’t just trapped in massive data centers—it is everywhere. It is in your watch, your car, your glasses, and your pocket. The most intelligent models of the future won’t be the biggest; they will be the most optimized.















